

房價預測或是說商品價格預測是一個典型的 AI 設計, 我們就採用資料容易取得的 “加州房價預測 (California Housing Prediction)” 來做這次的Demo code, 學習者可以透過這樣的內容進行模擬修改, 將學習資料置換成爲你手邊有的資訊來進行測試微調.
程式碼說明 Concept
1. 資料載入 (fetch_california_housing):
a. 我們不用 Excel 開檔案,直接用程式碼抓資料。
b.這裡的 y (房價) 單位是「10萬美元」。如果看到數值是 4.5,代表房價是 45 萬美元。
2. 資料切分 (train_test_split):
我們用了 80/20 法則。模型只會看到 80% 的資料來學習,剩下的 20% 是用來考試的。這確保了我們評估出來的分數是真實的。
3. 標準化 (StandardScaler):
這是一個關鍵的小技巧。因為「人口數」可能是 1000,「房間數」可能是 3。如果不縮放,模型可能會誤以為人口數比較重要(因為數字大)。
標準化把大家都變成「標準差」的單位,公平競爭。
4. 模型訓練 (LinearRegression):
a. model.fit() 這一行就是魔法發生的地方。電腦正在計算一條公式:$Price = w_1 \times (收入) + w_2 \times (屋齡) + \dots + b$
b. 它試圖找出最好的 $w$ (權重) 讓誤差最小。
5. 評估指標 (MSE 與 R2):
a. MSE (均方誤差): 預測值跟真實值平均差了多少的平方。數字越小,代表誤差越小。
b. R2 Score (決定係數): 最重要的指標。
1.0 = 完美預測。
0.6 = 還不錯。
0.0 = 跟瞎猜平均值一樣。
通常這個簡單的線性模型能跑到 0.60 (60%) 左右,這在初學階段是非常正常的表現。
Output 圖表說明(下方有產生的圖表範例)
執行後會跳出一張圖:
X 軸是真實的房價,Y 軸是模型猜的房價。
中間有一條紅色虛線。
如果所有的藍點都緊貼著紅色虛線,代表模型超級準。
如果藍點散得很開,代表模型還有很多進步空間(這時候就可以考慮換成更強的隨機森林模型,或深度學習模型)。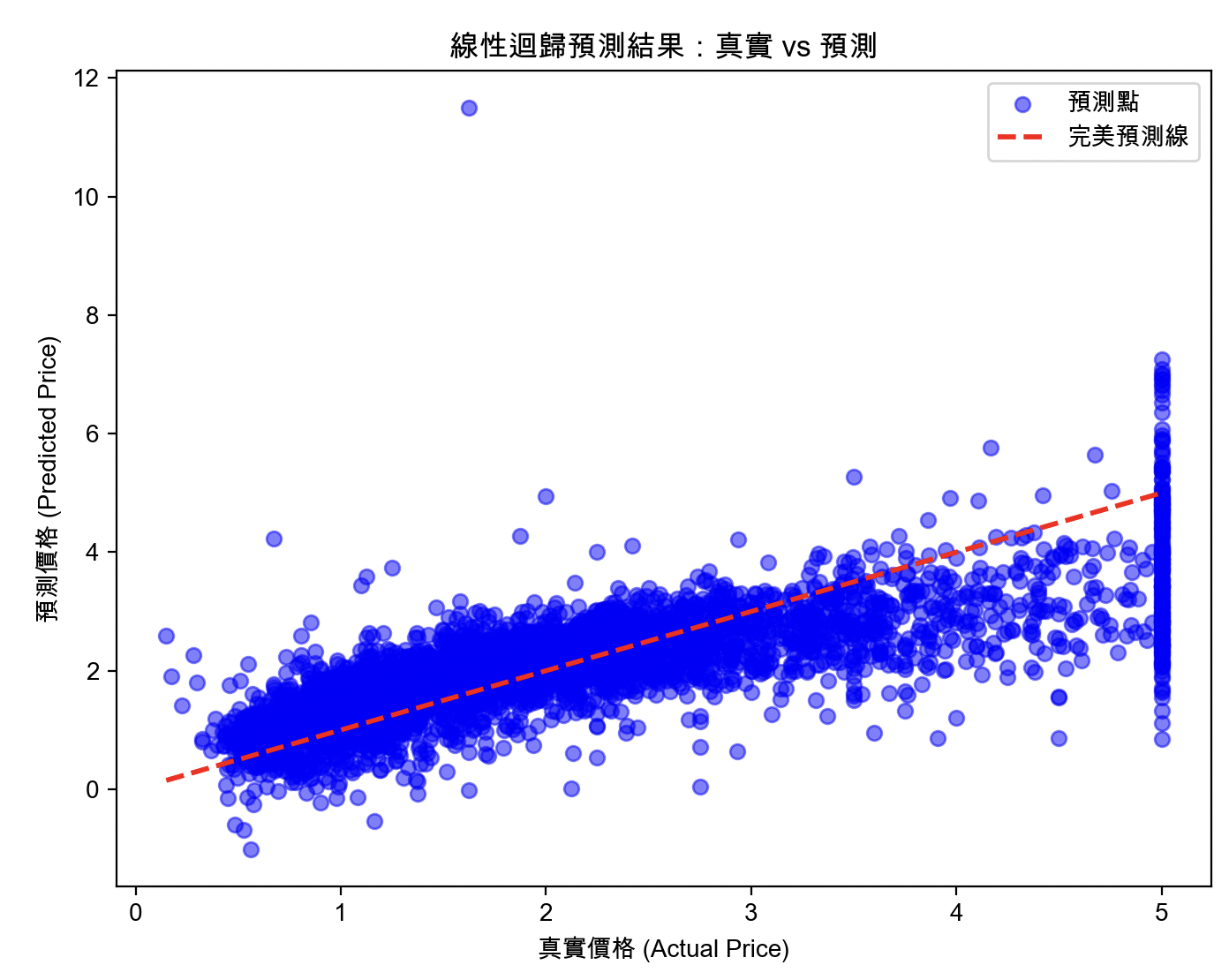
demo code
# 這個 demo 採用 線性迴歸 (Linear Regression)」 模型
# 引入必要的套件
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import mean_squared_error, r2_score
# --- 設定中文字型 (macOS 專用,避免亂碼警告) ---
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS']
plt.rcParams['axes.unicode_minus'] = False
# ----------------------------------------
# ---------------------------------------------------------
# 第一步:載入資料
# ---------------------------------------------------------
print("正在載入資料集...")
housing_data = fetch_california_housing()
# 將資料轉換成 Pandas DataFrame
df_X = pd.DataFrame(housing_data.data, columns=housing_data.feature_names)
df_y = pd.Series(housing_data.target, name='MedHouseVal')
# ---------------------------------------------------------
# 第二步:資料切分 (80% 訓練, 20% 測試)
# ---------------------------------------------------------
print("正在切分資料...")
X_train, X_test, y_train, y_test = train_test_split(
df_X, df_y, test_size=0.2, random_state=42
)
# ---------------------------------------------------------
# 【新增步驟】:將切分後的資料存成 CSV
# ---------------------------------------------------------
# print("正在匯出 CSV 檔案...")
#
# # 1. 合併特徵 (X) 與目標 (y) 以便存檔
# train_df = pd.concat([X_train, y_train], axis=1)
# test_df = pd.concat([X_test, y_test], axis=1)
#
# # 2. 寫入 CSV 檔案 (index=False 代表不要把 0,1,2... 這種索引數字寫進去)
# train_df.to_csv('training_data.csv', index=False)
# test_df.to_csv('testing_data.csv', index=False)
#
# print(f"成功儲存: training_data.csv (共 {len(train_df)} 筆)")
# print(f"成功儲存: testing_data.csv (共 {len(test_df)} 筆)")
# print("-" * 30)
# ---------------------------------------------------------
# 第三步:特徵標準化 (Standardization)
# ---------------------------------------------------------
# 注意:我們通常不對 target (房價) 做標準化,只對 features (X) 做
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# ---------------------------------------------------------
# 第四步:建立並訓練模型
# ---------------------------------------------------------
print("正在訓練線性迴歸模型...")
model = LinearRegression()
model.fit(X_train_scaled, y_train)
print("模型訓練完成!")
# ---------------------------------------------------------
# 第五步:模型評估
# ---------------------------------------------------------
y_pred = model.predict(X_test_scaled)
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
print("-" * 30)
print("【模型評估報告】")
print(f"1. 均方誤差 (MSE): {mse:.4f}")
print(f"2. 決定係數 (R2 Score): {r2:.4f}")
# ---------------------------------------------------------
# 第六步:視覺化結果
# ---------------------------------------------------------
plt.figure(figsize=(8, 6))
plt.scatter(y_test, y_pred, alpha=0.5, color='blue', label='預測點')
# 畫出完美預測線
plt.plot([y_test.min(), y_test.max()], [y_test.min(), y_test.max()], 'r--', lw=2, label='完美預測線')
plt.xlabel('真實價格 (Actual Price)')
plt.ylabel('預測價格 (Predicted Price)')
plt.title('線性迴歸預測結果:真實 vs 預測')
plt.legend() # 顯示圖例
plt.show()透過 code 取得的房屋資料程式碼會另存成 csv 檔案, 內容解說如下
這個 California Housing Dataset (加州房價資料集) 其實源自於 1990 年的美國人口普查資料。裡面的每一筆資料(每一列),
代表的不是「一棟房子」,而是一個街區 (Block Group) 的統計數據。一個街區通常包含好幾百人或好幾百個家庭詳細說明:
透過 API 取得的資料匯出:
