MNIST 是學習機器學習(ML)和深度學習(DL)的基石。它非常適合用來:
熟悉工具: 學習如何使用 TensorFlow 或 PyTorch
理解流程: 完整走過一遍 ML 的標準流程 (資料載入, 預處理, 建立模型, 訓練, 評估)
快速驗證: 資料集很小, 訓練速度快, 能在幾分鐘內看到結果, 這對於初學者建立信心至關重要
由於它被廣泛使用, 因此很適合作為一個「基準測試」, 來確保您的開發環境和程式碼是正確的. 另外幾乎所有能想到的 ML/DL 教學文章、課程或影片,都以 MNIST 作為第一個範例. 您在學習過程中遇到任何問題, 都能立即找到解答.
接下來可以的延伸方向
Fashion-MNIST
這是什麼? 這是一個由 Zalando(歐洲時尚電商)推出的資料集,格式與 MNIST 完全相同(28×28 灰階圖片,10 個類別),但內容是衣服、鞋子、包包等時尚單品. 它的難度比 MNIST 高得多, 更能真正測試您模型的效能, 被認為是 MNIST 的 [直接升級版]
更複雜的電腦視覺 (CV) 任務
CIFAR-10 / CIFAR-100: 另一個經典資料集, 包含 10 個或 100 個類別的彩色小圖片(如飛機、汽車、鳥類)
物件偵測 (Object Detection): 不只是分類, 還要能「框出」物體在哪裡. 您可以試著用 YOLO (You Only Look Once) 模型來偵測影像中的行人或車輛
跨足不同領域:
自然語言處理 (NLP): 建立一個「假新聞偵測器」, 「電影評論情緒分析」或使用小型語言模型(如 Llama 3 或 Gemma)的聊天機器人
時間序列 (Time Series): 分析並預測股票價格或天氣數據。
Simple 手寫辨識 demo code
# 檔案名稱: TensorFlow_Keras.py
# 此程式會透過 api 去網路上取得訓練資料與驗證資料並將之存檔為 mnist_local_cache.npz 以便下次使用
# 當程式跑完之後就將訓練好的模型存檔為今日日期的 keras 檔案, i.e. mnist_model_2025-12-17.keras
import tensorflow as tf
import numpy as np # 用來處理和儲存矩陣資料
import os
import datetime
# ---------------------------------------------------------
# 設定檔名變數
# ---------------------------------------------------------
# 1. 設定資料快取檔名 (存成壓縮的 numpy 格式)
data_filename = 'mnist_local_cache.npz'
# 2. 設定模型檔名 (包含今天日期,格式為 .keras)
current_date = datetime.datetime.now().strftime("%Y-%m-%d")
model_filename = f"mnist_model_{current_date}.keras"
# ---------------------------------------------------------
# 第一部分:載入資料 (實作資料快取)
# ---------------------------------------------------------
print("-" * 30)
if os.path.exists(data_filename):
print(f"✅ 發現本地資料檔:{data_filename}")
print("直接從硬碟載入,不透過網路下載...")
# 載入 .npz 檔案
with np.load(data_filename) as data:
x_train = data['x_train']
y_train = data['y_train']
x_test = data['x_test']
y_test = data['y_test']
else:
print(f"⚠️ 未發現本地資料,正在從網路下載 MNIST...")
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
print(f"正在將資料儲存到本地:{data_filename} ...")
# 將四個變數壓縮存入一個檔案
np.savez(data_filename, x_train=x_train, y_train=y_train, x_test=x_test, y_test=y_test)
print("資料載入完成!")
# 資料前處理 (正規化) - 不管是下載的還是讀檔的,都要做這一步
x_train, x_test = x_train / 255.0, x_test / 255.0
# ---------------------------------------------------------
# 第二部分:模型處理 (實作略過訓練)
# ---------------------------------------------------------
print("-" * 30)
# 檢查「今天的」模型檔案是否存在
if os.path.exists(model_filename):
print(f"🚀 發現今日已訓練好的模型:{model_filename}")
print("跳過訓練步驟,直接載入模型...")
# 直接載入模型
model = tf.keras.models.load_model(model_filename)
else:
print(f"🐢 未發現今日模型,開始建立並訓練新模型...")
# 建立模型 (使用新版 Input 寫法)
model = tf.keras.models.Sequential([
tf.keras.Input(shape=(28, 28)),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(10)
])
# 編譯模型
loss_fn = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)
model.compile(optimizer='adam',
loss=loss_fn,
metrics=['accuracy'])
# 開始訓練
model.fit(x_train, y_train, epochs=5)
# 訓練完後存檔 (使用 .keras 格式)
print(f"正在儲存模型至:{model_filename} ...")
model.save(model_filename)
print("模型儲存完成!")
# ---------------------------------------------------------
# 第三部分:模型評估 (無論是新舊模型,都進行評估)
# ---------------------------------------------------------
print("-" * 30)
print("正在評估模型表現...")
# 使用 verbose=2 簡化輸出訊息
model.evaluate(x_test, y_test, verbose=2)驗證 手寫辨識 demo code
# 檔案名稱: VerifyMine.py
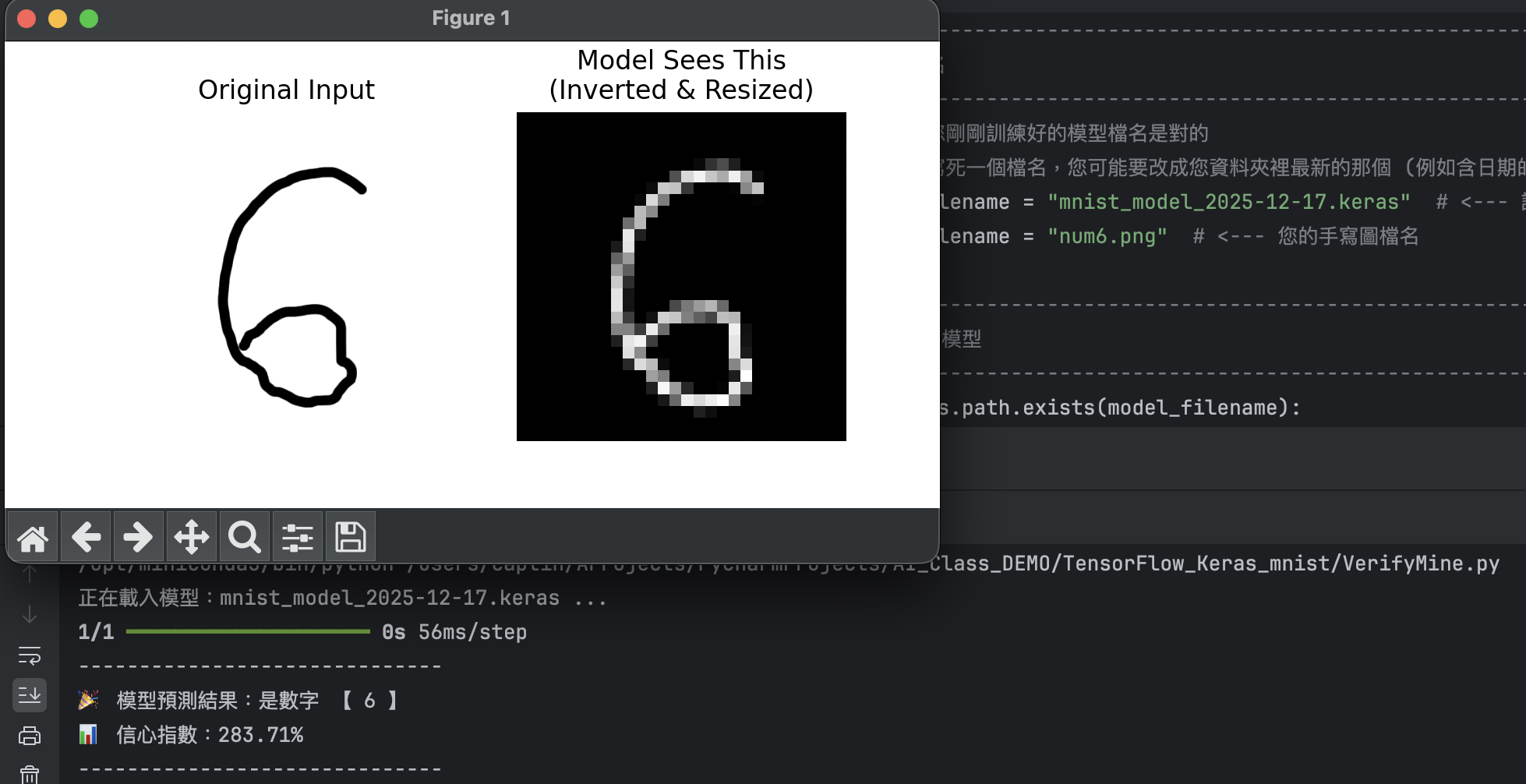
# 事前準備工作, 用一張正方形, 白底, 黑字的手寫數字 png 檔案, 作為給 AI 辨識用的測試data
# 我們在 demo code 用的檔名叫做 num6.png, 內容可參考下方圖示
# 手動安裝 lib, pip3 install opencv-python matplotlib
import tensorflow as tf
import cv2 # OpenCV 影像處理
import numpy as np
import matplotlib.pyplot as plt
import os
# 需要在環境內安裝套件
# pip install opencv-python matplotlib
# ---------------------------------------------------------
# 設定檔名
# ---------------------------------------------------------
# 請確保您剛剛訓練好的模型檔名是對的
# 這裡我寫死一個檔名,您可能要改成您資料夾裡最新的那個 (例如含日期的)
model_filename = "mnist_model_2025-12-17.keras" # <--- 請修改這裡對應您的檔名
image_filename = "num6.png" # <--- 您的手寫圖檔名
# ---------------------------------------------------------
# 1. 載入模型
# ---------------------------------------------------------
if not os.path.exists(model_filename):
print(f"❌ 找不到模型檔案:{model_filename},請先執行訓練程式!")
exit()
print(f"正在載入模型:{model_filename} ...")
model = tf.keras.models.load_model(model_filename)
# ---------------------------------------------------------
# 2. 影像前處理函數 (關鍵步驟!)
# ---------------------------------------------------------
def preprocess_image(image_path):
# A. 讀取圖片 (轉為灰階模式)
# cv2.IMREAD_GRAYSCALE 會直接把 RGB 轉成單色
img = cv2.imread(image_path, cv2.IMREAD_GRAYSCALE)
if img is None:
print(f"❌ 讀取圖片失敗:{image_path}")
return None
# B. 調整大小 (Resize)
# MNIST 的標準尺寸是 28x28
# 使用 INTER_AREA 插值法,縮小圖片時效果較好
img_resized = cv2.resize(img, (28, 28), interpolation=cv2.INTER_AREA)
# C. 顏色反轉 (Invert) - 超級重要!!!
# 原本是「白底黑字」(255底, 0字) -> 要轉成「黑底白字」(0底, 255字)
img_inverted = cv2.bitwise_not(img_resized)
# D. 正規化 (Normalize)
# 把數值從 0~255 壓縮到 0.0~1.0
img_normalized = img_inverted / 255.0
# E. 改變形狀 (Reshape)
# 模型預期一次吃一批資料,形狀要是 (數量, 28, 28)
# 所以我們把 (28, 28) 變成 (1, 28, 28)
img_ready = img_normalized.reshape(1, 28, 28)
return img_ready, img_inverted
# ---------------------------------------------------------
# 3. 執行預測
# ---------------------------------------------------------
if not os.path.exists(image_filename):
print(f"❌ 找不到手寫圖片:{image_filename},請先用小畫家畫一張!")
else:
# 呼叫處理函數
result = preprocess_image(image_filename)
if result:
input_data, processed_img_for_viewing = result
# 進行預測
prediction = model.predict(input_data)
# 取出機率最高的數字 (argmax)
predicted_number = np.argmax(prediction)
confidence = np.max(prediction) # 信心指數
print("-" * 30)
print(f"🎉 模型預測結果:是數字 【 {predicted_number} 】")
print(f"📊 信心指數:{confidence:.2%}")
print("-" * 30)
# -----------------------------------------------------
# 4. 畫出來檢查 (Debug)
# 讓我們看看模型實際上「看」到了什麼
# -----------------------------------------------------
plt.figure(figsize=(6, 3))
# 左邊畫原本讀入的圖 (雖然已被 Resize)
plt.subplot(1, 2, 1)
plt.imshow(cv2.imread(image_filename), cmap='gray')
plt.title("Original Input")
plt.axis('off')
# 右邊畫模型真正看到的圖 (黑底白字)
plt.subplot(1, 2, 2)
plt.imshow(processed_img_for_viewing, cmap='gray')
plt.title("Model Sees This\n(Inverted & Resized)")
plt.axis('off')
plt.show()num6.png => 
測試結果